


Ja si të përfitoni maksimumin nga GPT-5
Nga The PyCoach
Shumica e përdoruesve nuk po e shfrytëzojnë plotësisht potencialin e GPT-5.
Pse? Sepse për të përfituar maksimumin nga GPT-5 kërkohet njohuri me teknikat e dhënies së udhëzimeve (prompting) dhe cilësimet e parametrave për të maksimizuar cilësinë e rezultateve të tij.
Unë kam kaluar shumë orë duke studiuar udhëzuesin e OpenAI për përdorimin e GPT-5 për të kuptuar më mirë se si të përfitoj maksimumin nga modeli, si përmes aplikacionit të uebit ChatGPT, ashtu edhe përmes OpenAI Playground. Në këtë udhëzues, do t’i shpjegoj rekomandimet e OpenAI për dhënien e udhëzimeve në gjuhë të thjeshtë, duke shmangur pjesën më të madhe të zhargonit teknik që gjendet në udhëzuesin zyrtar.
#1 Optimizoni ndjekjen e udhëzimeve
GPT-5 i ndjek udhëzimet me saktësi të madhe, gjë që është një avantazh në shumicën e rasteve, por nëse udhëzimi juaj (prompt-i) është i paqartë ose përmban udhëzime kontradiktore, modeli mund të ngatërrohet ose të humbasë kohë duke u përpjekur t’i pajtojë konfliktet.
Për shembull, mos thoni “Jep një përmbledhje të shkurtër” dhe më vonë në të njëjtin udhëzim të thoni “Përfshi të gjitha detajet.”
Pse është kjo gabim? Udhëzimet kontradiktore do ta prishin përgjigjen, pasi modeli nuk do të dijë se cilës t’i japë përparësi. Këshilla këtu është të kontrolloni gjithmonë dy herë udhëzimin tuaj për çdo mesazh të paqartë. Hiqni ose sqaroni çdo gjë që mund të interpretohet në mënyra të shumta.
Sipas OpenAI, pastrimi i paqartësive dhe kontradiktave në udhëzime e përmirëson në mënyrë drastike performancën e GPT-5.
Ju mund të përdorni ChatGPT për të gjetur konflikte në udhëzimin tuaj:
Shqyrto udhëzimet e mia. Gjej çdo konflikt. Sugjero ndryshimet më të vogla për t’i bërë udhëzimet konsistente.
Ose mund të përdorni optimizuesin e udhëzimeve të OpenAI për të rishikuar udhëzimin tuaj. Do ta shohim këtë në detaje në pikën tjetër.
#2 Përdorni optimizuesin e udhëzimeve të OpenAI
OpenAI ka një optimizues udhëzimesh për GPT-5 të disponueshëm në Playground. Playground është një platformë e dizenjuar për përdorues të avancuar për të zgjedhur modele të ndryshme, për të rregulluar parametrat e modelit dhe më shumë (në fakt, do të përdorim Playground nga këshilla #3 e tutje).
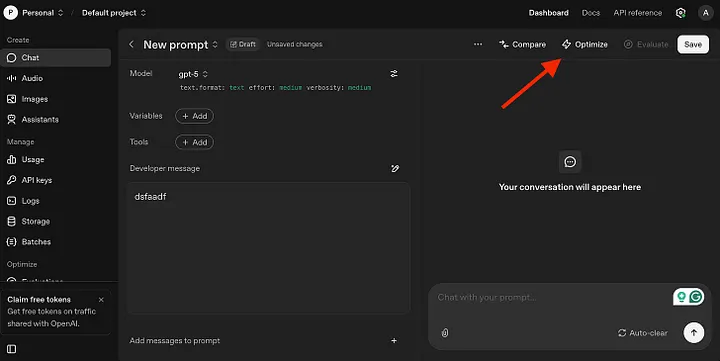
Një nga gjërat e lezetshme që mund të gjejmë në Playground është optimizuesi i udhëzimeve.
Për të përdorur optimizuesin e udhëzimeve, klikoni këtu dhe hyni me llogarinë tuaj të ChatGPT. Më pas, shkruani ose ngjisni udhëzimin tuaj dhe klikoni “Optimize” për të marrë reagime. Pasi udhëzimi juaj të optimizohet, mjeti do të theksojë ndryshimet me ngjyrë blu, dhe ikonat e shënimeve në të djathtë do të ofrojnë arsyetimin pas atyre ndryshimeve.
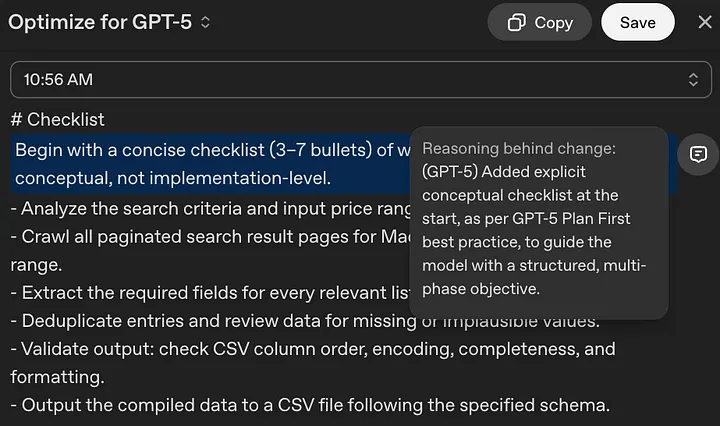
Mjeti është i dobishëm, por është ende e nevojshme të mësoni këshillat shtesë në këtë udhëzues për të kuptuar ndryshimet që bën dhe për të njohur kur ato ndryshime janë të nevojshme.
Këshillat për dhënien e udhëzimeve nga kjo pikë e tutje mund të aplikohen përmes API-së ose OpenAI Playground. Playground nuk kërkon njohuri programimi dhe unë e rekomandoj fuqimisht përdorimin e tij sa herë që aplikacioni i uebit ChatGPT nuk ju mjafton dhe keni nevojë për më shumë kontroll mbi GPT-5.
#3 Kontrolloni përpjekjen për arsyetim (reasoning effort)
GPT-5 ka një parametër reasoning_effort për të kontrolluar sa thellë mendon modeli dhe sa i gatshëm është të përdorë mjete. Vlera e paracaktuar është medium (e mesme), por ju duhet ta rrisni ose ulni në varësi të vështirësisë së detyrës suaj.
Për të kontrolluar përpjekjen për arsyetim, klikoni ikonën e rregullimit të cilësimeve në Playground.
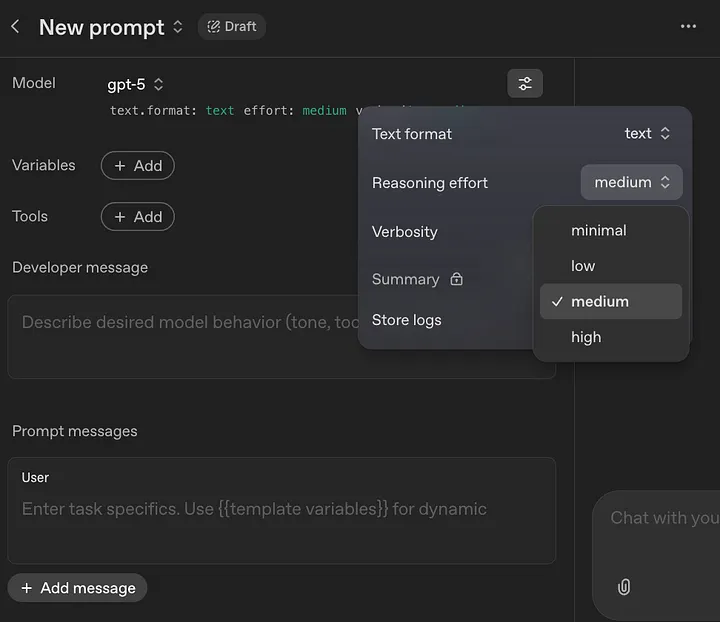
Ekzistojnë 4 nivele të përpjekjes për arsyetim:
-
minimal: U prezantua në GPT-5 dhe i thotë modelit të bëjë sa më pak të menduar të jetë e mundur për t’ju dhënë një përgjigje. Është projektuar të jetë i shpejtë dhe është ideal për detyra deterministike e të lehta (ekstraktim, formatim, rishkrime të shkurtra, klasifikim i thjeshtë).
-
low (i ulët): Angazhohet në pak më shumë të menduar, por ende i jep përparësi të madhe efikasitetit. I besueshëm për gjëra që kërkojnë pak kuptim, por jo zgjidhje të thellë e kreative të problemeve. I mirë për mbështetje standarde për klientët, përmbledhje përmbajtjesh, etj.
-
medium (i mesëm): Është cilësimi i paracaktuar. Ofron një ekuilibër midis performancës dhe shpejtësisë. Është niveli ku IA me të vërtetë fillon të “mendojë”. Përgjigjet janë më gjithëpërfshirëse, kreative dhe të strukturuara mirë. I mirë për krijimin e përmbajtjes, gjenerimin e kodit, analizën dhe ndjekjen e udhëzimeve komplekse.
-
high (i lartë): I thotë GPT-5 të marrë gjithë kohën që i nevojitet dhe të përdorë sa më shumë “tokena” arsyetimi të jetë e nevojshme përpara se t’ju japë një përgjigje. I shkëlqyeshëm për detyra ku saktësia është kritike, si kërkimi shkencor dhe akademik, planifikimi strategjik dhe korrigjimi i kodeve të vështira. Mund të jetë i ngadaltë dhe i kushtueshëm.
Mbani në mend se përpjekja minimale për arsyetim mund të ndryshojë më drastikisht në varësi të udhëzimit sesa nivelet më të larta të arsyetimit.
OpenAI rekomandon që GPT-5, kur vendoset në arsyetim minimal, të përshkruajë së pari qasjen. Për shembull, mund të thoni: “Së pari, listo hapat që do të ndërmarrësh për të zgjidhur problemin.” Edhe një plan me një fjali ose disa pika strategjie në fillim të përgjigjes mund të përmirësojë performancën në detyrat që kërkojnë inteligjencë më të lartë.
#4 Kontrolloni gatishmërinë agjentike (proaktivitetin)
Duke kontrolluar reasoning_effort ne mund të kalibrojmë gjithashtu gatishmërinë agjentike të GPT-5 (nëse modeli është më proaktiv apo jo).
-
Më shumë gatishmëri: Inkurajon autonominë e modelit dhe redukton rastet e pyetjeve sqaruese ose kthimin e përgjegjësisë te përdoruesi.
Për të marrë më shumë gatishmëri, duhet të rrisni reasoning_effort dhe të përdorni një udhëzim që inkurajon këmbënguljen dhe përfundimin e plotë të detyrës. Ja një shembull i mirë udhëzimi për të marrë më shumë gatishmëri (nxjerrë nga udhëzuesi i OpenAI):-
Ti je një agjent — të lutem vazhdo derisa kërkesa e përdoruesit të zgjidhet plotësisht, përpara se të përfundosh radhën tënde dhe t’ia kthesh fjalën përdoruesit.
-
Përfundoje radhën tënde vetëm kur të jesh i sigurt se problemi është zgjidhur.
-
Asnjëherë mos u ndal ose mos ia kthe fjalën përdoruesit kur has pasiguri — hulumto ose dedukto qasjen më të arsyeshme dhe vazhdo.
-
Mos i kërko njeriut të konfirmojë ose sqarojë supozimet, pasi gjithmonë mund të përshtatesh më vonë — vendos cili është supozimi më i arsyeshëm, vazhdo me të dhe dokumentoje për referencë të përdoruesit pasi të përfundosh veprimin.
-
-
Më pak gatishmëri: Si parazgjedhje, GPT-5 është mjaft i plotë. Ai përpiqet të mbledhë shumë kontekst për të siguruar përgjigje të sakta. Ju mund ta reduktoni sjelljen e mbledhjes së kontekstit për të marrë përgjigje më të ngushta dhe më të shpejta duke kaluar në një reasoning_effort më të ulët dhe duke përcaktuar kritere të qarta në udhëzimin tuaj se si doni që modeli të eksplorojë hapësirën e problemit.
Më poshtë janë disa udhëzime që mund t’i shtoni udhëzimit tuaj për të reduktuar sjelljen e mbledhjes së kontekstit:-
Shmang kërkimin e tepërt për kontekst.
-
Nëse mendon se ke nevojë për më shumë kohë për të hetuar, përditësoje përdoruesin me gjetjet e tua më të fundit dhe pyetjet e hapura. Mund të vazhdosh nëse përdoruesi konfirmon.
-
Përpiqu fuqimisht të japësh një përgjigje të saktë sa më shpejt të jetë e mundur, edhe nëse mund të mos jetë plotësisht e saktë.
-
Vini re se pjesa “edhe nëse mund të mos jetë plotësisht e saktë” ndihmon t’i ofrojë modelit në mënyrë eksplicite një rrugëdalje që e bën më të lehtë përmbushjen e një hapi më të shkurtër të mbledhjes së kontekstit.
#5 Kontrolloni verbositetin (fjalëshumësinë)
OpenAI prezantoi një parametër të ri API në GPT-5 të quajtur verbosity, i cili ndikon në gjatësinë e përgjigjes përfundimtare të modelit. Tani mund t’i kërkoni modelit të angazhohet në më shumë ose më pak arsyetim duke përdorur reasoning_effort, ndërsa rregulloni në mënyrë të pavarur gjatësinë e përgjigjes së tij përfundimtare me verbosity.
Si ndihmon kjo?
Ju kujtohen udhëzimet kontradiktore për të cilat folëm në pikën #1? Epo, në Playground, nuk do t’ju duhen mashtrime delikate në udhëzime si “ji konciz”, sepse mund ta kontrolloni atë me parametrin verbosity.
Kjo redukton udhëzimet kontradiktore dhe përmirëson respektimin e udhëzimeve aktuale të detyrës.
Ekzistojnë 3 nivele të verbositetit: low (i ulët), medium (i mesëm) dhe high (i lartë). Nëse e vendosni verbositetin në “low,” përgjigjet e modelit do të jenë të shkurtra, të drejtpërdrejta dhe efikase, ndërsa “high” do të japë përgjigje më të gjata dhe më të detajuara.
Ja një shembull i thjeshtë për 3 nivelet e verbositetit:
-
Përdoruesi: Cili është kryeqyteti i Francës?
-
Modeli (verbositet i ulët): Parisi.
-
Modeli (verbositet i mesëm): Kryeqyteti i Francës është Parisi.
-
Modeli (verbositet i lartë): Kryeqyteti i Francës është Parisi. Ai është qyteti më i madh në vend dhe shërben si qendra e tij politike, kulturore dhe ekonomike.



 – Fatmir Baçi")

